In Chinese culture, the panda bear is considered be a symbol of peace. So why did Google name one of their best known – or maybe most notorious is more like it – major algorithm updates that has caused a lot of headaches in the SERP’s over the past few years after this wonderful animal?
To be ironic?
Who knows, but since there are a lot of people that are trying to figure out how to “beat” it (first step, stop always being reactive) and there is a ton of speculation out there on it, I want to take a few minutes to distill what’s being said with a few thoughts.
A Quick Recap Of Panda
Google makes hundreds of tweaks to their search algorithm every year, but the updates that are especially impactful typically get internal code names like Vince, Caffeine, Hummingbird (this is a core rewrite to a major part of their natural language query engine, so calling it an update is an understatement), Penguin and Panda.
The Panda updates are geared towards content quality on a website and are intended to boost higher quality sites while punishing other site’s that have primarily two things:
- Thin or spammy content
- Duplicate content
The idea with the Panda updates is to try and send searchers to sites with high quality, helpful, unique and relevant content that’s going to satisfy the intention behind their query in the best way possible. One could definitely argue that’s the point of Google’s entire search algorithm, but this is all about the content side of the equation.

Ask.com gets Eaten By A Rabid Panda
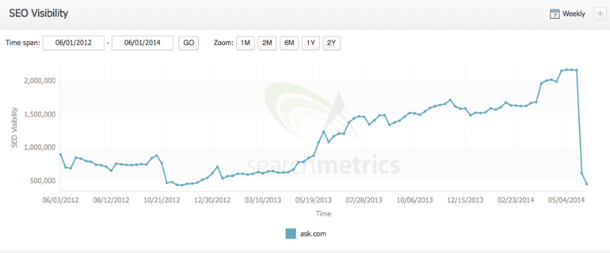
Since there’s not currently a lot of hard data out there on what exactly is being targeted other than the general stuff I mentioned above, I wanted to provide a quick example of a site that got hit hard which will hopefully provide some insights.
Disclaimer: I don’t mean this as a post to call out Ask.com for doing anything wrong, since I think this is an extreme example of a site being de-ranked vs. completely penalized. The former rewards competitors for producing better content while the latter is a direct slap to the face with a stern “No!” in response for doing something against Google Webmaster’s Guidelines which often results in dropping 100+ spots. Hopefully, they’ll bounce back soon.
As you can see, Ask.com saw a MASSIVE drop which coincides with Panda 4.0 which was officially announced early evening on 5/20/14. Many SERP trackers like Mozcast and Algoroo saw big fluctuations earlier than that, though.

Considering there was another announced update which reported went into effect around May 17th or so which targets traditionally spammy queries/niches like payday loans, it’s hard to tell exactly which update we’re dealing with. It could very well be a combination of the two depending on the verticals each tracker is targeting. Nonetheless, you can see that there was a pretty large shakeup in SERP’s around then.
So Where Did They Lose Visibility, And What May Have Caused It?
When I dug into what may have happened using one of my favorite tools, Searchmetrics, I immediately noticed that the vast majority of the drop happened with a handful of specific subdirectories. So what’s going on with them that could have caused the panda to get so angry?

Scraped Content From Other Authority Sites
So let’s check out some pages in the /question/ subdirectory to see if we can find some things from a content standpoint that might be causing the cataclysm.
Considering that I work in the web hosting industry, I decided to check out questions related to “Web Hosting & Domain Registration”, and a question about TLD’s (Top Level Domains) immediate stood out to me. Here’s what I found when I clicked over to the page:

I immediately noticed how little unique content is on the page, since the vast majority is just scrapped from other sources like eHow and Wikipedia. Even the direct answer to the question at the top of the page appears to be part of the Wikipedia description on the right with an additional sentence. No bueno.
When I clicked through to the Wikipedia link on to top right, I’m taken to what is essentially an entire scraped post from this Wikipedia page.
What About User Experience?
When it comes down to one of the main things that Google cares about, the user’s experience, I don’t think that Ask.com is 100% in the wrong. Sure, it would be much more valuable if they expanded on the topic by including unique additional reading that they produced vs. scraping it from other sites, but I also think that there’s value from the searcher’s perspective in having these related resources available on one page. In this example, the question is answered, and there’s additional reading that’s readily available without having to go back to Google if the searcher needs more information.
That seems like a good user experience to me, but I think this is definitely one of those cases where both sides can be argued, especially since there are so many sites that do similar things which don’t add any value to the user.
What do you think?
Do sites which primarily just act as content syndicators provide value to their users?
Should search engines like Google show the multiple sources to the searcher instead?
Is Google overstepping its bounds by essentially forcing the internet to adhere to its vision/standards vs. just arranging and displaying the world’s knowledge as they originally intended?
Google’s Thirst For Quality Content Continues
While this isn’t intended to be a definitive case study on Panda 4.0, I think provides some possible examples of why a huge site lost a lot of visibility in Google due to thin and/or duplicate content issues with some of their top subdirectories.
If there’s enough interest, I’d be happy to take a deeper dive into additional large sites that may have been affected by Panda 4.0, so if you’d like to see that, please let me know in the comments!
As the SEO Manager for HostGator.com, Brian is responsible for the organic traffic strategy for the organization. In 2007, he left a successful career in the financial services industry to pursue is new budding passion; SEO and online marketing. Over the past seven years, he has worked with a handful of large agencies working on campaigns ranging from local businesses all over the country to large organizations like the USDA. His primary area of focus is advanced technical onpage SEO.
When he’s not geeking out over the ever evolving SEO landscape or testing theories on his own websites, Brian is a budding homebrewer, guitarist, avid gamer and marksmanship enthusiast.